
【Dify】Dify 2.0.0-betaリリース! ナレッジパイプラインと新エンジンで何が変わった?



サステックスのエンジニア、鈴木です。
2025年9月4日、オープンソースのAIノーコードアプリ開発プラットフォーム「Dify」の最新バージョンv2.0.0-beta.1(ベータ版)がリリースされました。DifyはChatGPTなどのLLM(大規模言語モデル)を用いたAIアプリをプログラミング不要で構築できるノーコードツールで、社内チャットボットやFAQシステム、データベース連携型のAIアプリなどをエンジニアでなくても簡単に作成できます。わずか1週間前にはDify v1.8.0がリリースされたばかりで、そこから間髪入れず2.0.0のベータ版が登場したことからも、その開発スピードと勢いの凄まじさがうかがえます。
前回までのDifyアップデート内容については以下の記事で詳しく紹介しています。
あわせて読みたい
あわせて読みたい


【Dify】Dify v1.8.0 アップデート解説:新機能と改善点まとめ
Difyが最新バージョン1.8.0へアップデート!マルチモデル対応の資格情報管理、OAuth統合、UI改善、ワークフロー性能向上など注目ポイントをエンジニア視点で解説。セキュリティ強化やバグ修正も網羅し、Dify初心者にも分かりやすく最新機能をご紹介します。
あわせて読みたい

社内FAQチャットボット構築ガイド:Difyのナレッジ機能で実現する効率的な問い合わせ対応
Difyのナレッジ機能で社内FAQチャットボットを簡単構築!問い合わせ対応を自動化し、業務効率を大幅に改善する方法を解説。
あわせて読みたい

【Dify】Dify上で外部検索を実現する方法4選|Dify公式プラグイン・Tavily・Google API・独自APIの徹底比較
Difyで外部検索を使う理由と導入方法を徹底解説。SerpAPIやTavily、Google Custom Search API、自作APIまでを比較し、費用・運用難易度・柔軟性の観点から最適な選択肢を紹介します。
本記事では、Dify 2.0.0-betaの新機能とアップデート内容を初心者にもわかりやすく徹底解説し、前バージョンから何が変わったのか整理します。特に今回のベータ版では「ナレッジパイプライン」と「キュー駆動型グラフエンジン(新ワークフロー実行エンジン)」という2つの大きな機能強化が行われており、法人でのAI活用をさらに前進させる内容になっています。AI活用に関心のある方や既にDifyをご利用中の方はぜひ参考にしてください。
目次
Difyとは?2.0.0ベータ版アップデートの背景
改めてDifyについておさらいしておきましょう。
Dify(ディフィ、ディファイ)は、ユーザーが自分だけのAIエージェントやワークフローを構築できる次世代のAI開発プラットフォームです。オープンソースで公開されており(GitHubで10万以上のスターを獲得)、ノーコードながら高度なAI/ML機能を駆使したAIアプリ開発が可能な点が大きな魅力です。
例えばプロンプト(指示文)のUI化による社内向けツールの作成、複数のLLMモデル(GPT-4やClaude、Google PaLMなど)を用途に応じて使い分け、企業内データを読み込ませて回答精度を高めるRAG(Retrieval-Augmented Generation)機能の活用など、現場で役立つAIアプリを迅速に開発できます。エンジニアでなくとも扱えるシンプルな操作性と迅速なデプロイが特長で、社内チャットボットや業務自動化ツールの「シチズンデベロップメント(市民開発)」を加速するプラットフォームとして注目されています。
2025年前半までの主なアップデートとして、ワークフロー機能の正式実装、RAG(外部データ連携)の高度化、プラグインSDK公開による外部サービス連携強化、AIエージェント機能の自律性向上、Google Sheets連携対応などが挙げられます。こうした更新により、Difyは単なる生成AIチャットツールから業務自動化プラットフォームへと進化を遂げつつありました。直近のv1.7.0~v1.8.0では、ワークフローとエージェント機能の大幅な強化や、複数モデル対応・セキュリティ改善などが行われ、企業での本格導入を見据えた機能拡充が続いています。
そして迎えたv2.0.0-betaでは、開発チームが掲げるテーマは「Orchestrating Knowledge, Powering Workflows」――知識のオーケストレーション(統合管理)とワークフローの強化です。その名の通り、ナレッジ(知識)パイプラインとキュー駆動型の新グラフエンジンという二本柱の改良が導入されました。開発者コミュニティから寄せられたフィードバックや要望に応える形で、企業利用でボトルネックとなっていた課題に取り組んでいます。
それでは具体的に、Dify 2.0.0-betaでどのような新要素が追加・改善されたのか、主要トピックごとに見ていきましょう。
ナレッジパイプライン:柔軟なドキュメント処理基盤の実現
まず注目すべきは「ナレッジパイプライン」と呼ばれる新機能です。
これはドキュメント(社内の各種資料やデータ)の取り込みから加工・保存までの一連の流れ(パイプライン)を視覚的に設計・制御できる機能で、企業内のナレッジ活用を飛躍的に高めるポテンシャルを持っています。
背景:RAG機能に残っていた課題
Difyは以前から社内データを読み込ませて回答に活用するRAG(Retrieval-Augmented Generation)の機能を備えていました。しかし実際に使ってみると、既存のナレッジ機能にはいくつかの課題が指摘されていました。弊社でも過去にDifyで社内FAQボットを作成する記事を書いた際に痛感しましたが、例えば以下のような点です。
- データソースの種類が限定的で、様々な形式の社内データを取り込むのに工夫が必要だった
- 表や画像を含むドキュメントをうまく扱えず、テキスト化で情報が抜け落ちるケースがあった
- 文書をチャンク(分割)する際に最適な単位の見極めが難しく、チャンクが不適切だと回答精度が低下する恐れがあった
実際、従来はFAQデータを読み込ませる際にも「1つのQ&Aペアが途中で別チャンクにちぎれないようにトークン長を調整する」など手作業の工夫が必要でした。チャンクサイズが合わずQ&Aが分断されてしまうと回答精度が落ちるため、長すぎる回答は要約したり設定値を再調整したりと試行錯誤する場面もあったのです。
解決策:オープンでモジュール化された知識処理アーキテクチャ
こうした課題に応えるため、Dify 2.0では知識データの処理基盤を根本から再構築しました。開発チームは「ナレッジパイプライン」を通じて、ドキュメントの取り込みからベクトルデータベースへの保存・検索に至るまでをオープンかつモジュール化されたパイプラインとして再定義しています。要するに、企業ごとのニーズに合わせて自由にカスタマイズ可能な知識処理ワークフローを実現したのです。
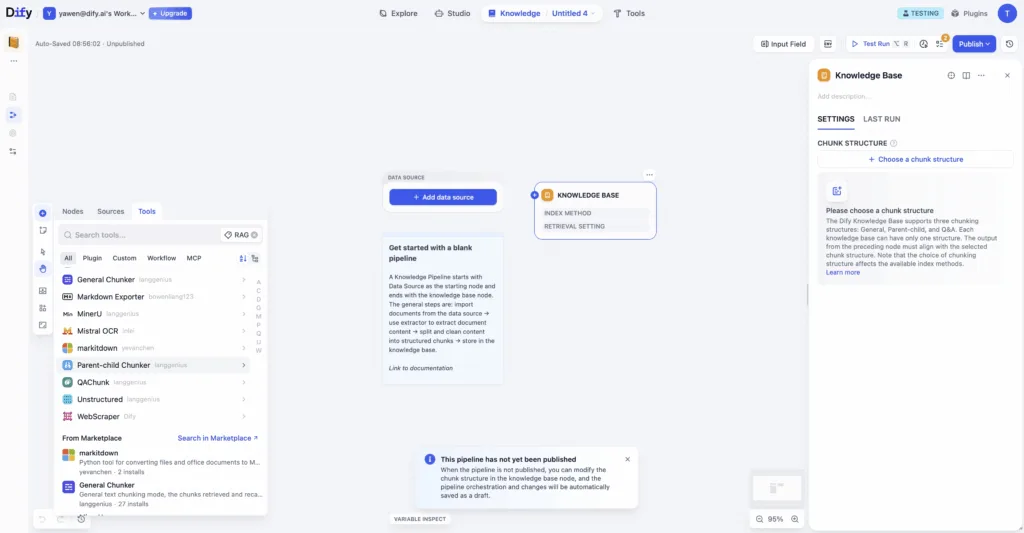
ナレッジパイプラインでは各処理ステップをノード(部品)としてビジュアルに組み合わせ、パイプライン全体をワークフローとして設計・実行できます。例えば「ファイルを読み込む」「テキスト抽出する」「チャンクに分割する」「ベクトルデータベースに格納する」といった各工程をパズルのピースのように繋ぎ合わせ、自社のドキュメント構造や精度要件に最適化した処理フローを組み立てられます。これにより「どのようにデータが処理・変換されているか」がブラックボックスにならず可視化でき、問題があれば途中段階で差し替えや調整も容易になりました。
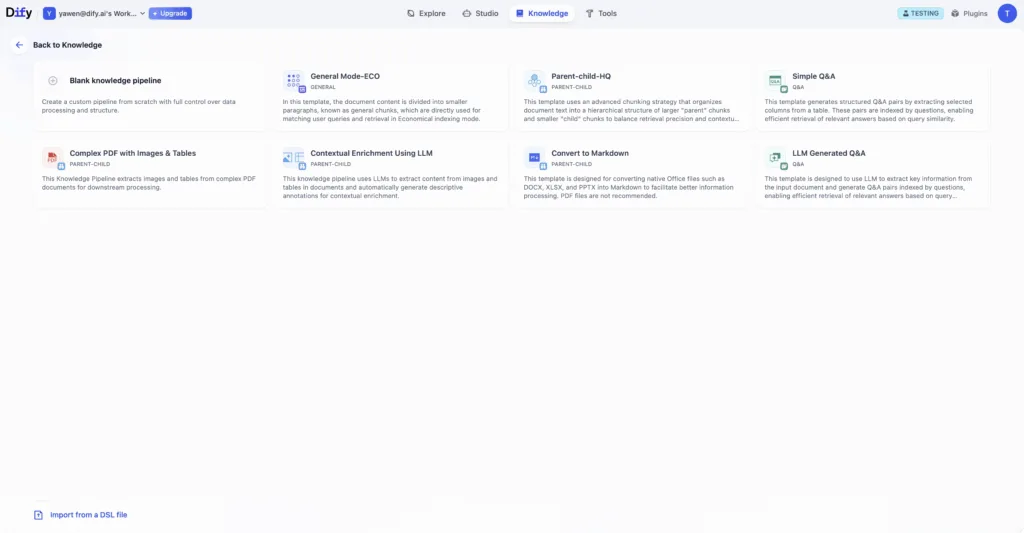
さらに、パイプラインには豊富な公式プラグインが用意されており、必要に応じて機能を拡張できます。各ナレッジベースごとに複数のデータソースをサポートしており、ローカルファイル、オンラインドキュメント、クラウドドライブ、ウェブクロールなど多彩なデータ取り込み手段をシームレスに統合できます。開発者が独自のデータソース・プラグインを追加することも可能で、例えば「社内の特殊なファイル形式に対応したパーサー」を自作して組み込むこともできます。またマーケットプレイスから利用できる各種プロセッサ(プラグイン)は、数式やスプレッドシート、画像解析など専門的な処理にも対応しており、テーブルや画像を含む資料でも正確に情報を抽出・構造化してナレッジ化できるようになりました。
新要素:Q&A特化のチャンク分割や画像対応など
ナレッジパイプラインでは、既存機能からの改良点も数多く盛り込まれています。特にチャンク分割(ドキュメントの分割方法)の強化は重要です。従来は汎用的な分割手法(一定長ごと、親子構造に基づく分割など)が提供されていましたが、新たにQ&A形式の文書構造に対応したチャンク分割が追加されました。
これによりFAQ集のように「質問→回答」がセットになったドキュメントでも、それぞれのQ&Aペアをひとまとまりのコンテキストとして扱いやすくなります。前述のようなQ&Aがチャンク分断される問題も、この専用プラグインにより自動で適切に対処できる可能性があります。
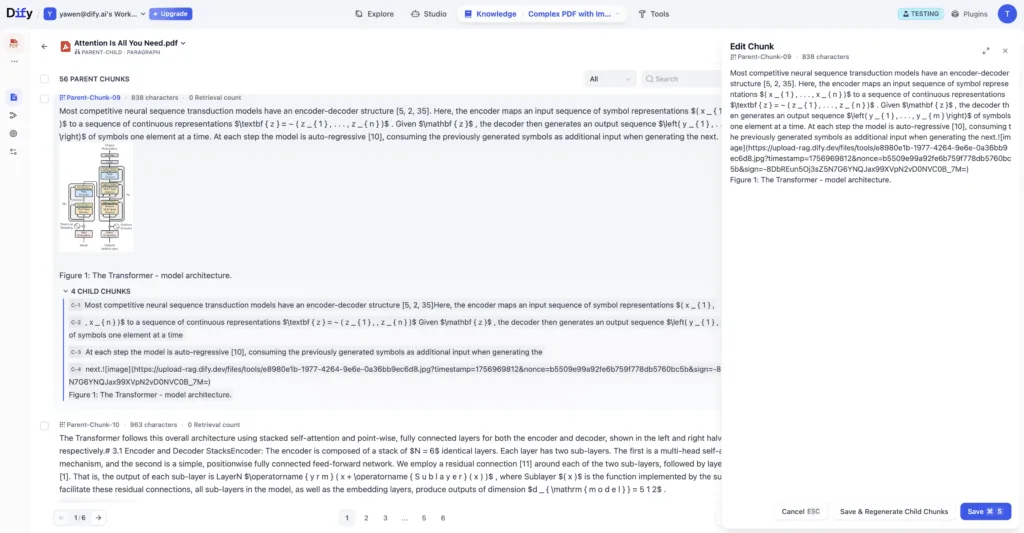
また画像を含むドキュメントへの対応も見逃せません。PDFやWord等から画像を抽出し、URLとしてナレッジベース内に格納する機能が加わりました。これによって生成AIが回答を作成する際に、テキストだけでなく関連する画像も引用してテキスト+画像のリッチな回答を返すことが可能になります。例えばマニュアルの図表や製品の写真なども含めた回答生成が期待でき、ユーザーにとってより実用的な応答が得られるでしょう。
さらにテンプレート機能とパイプラインDSLによるパイプライン共有も便利なポイントです。Dify公式が用意したテンプレートから出発してすぐにパイプラインを構築したり、完成したワークフローをDSL形式でエクスポート・インポートして他プロジェクトと共有したりといった柔軟な運用ができます。社内のベストプラクティスを他部署と共有したり、コミュニティ内で効果的なパイプライン構成を交換したりといった活用も今後広がりそうです。
開発・運用者に嬉しいデバッグ機能と移行支援
ナレッジパイプラインは開発段階での検証・デバッグも容易になっています。パイプライン公開前に各ステップを個別に実行して結果を確認できるテスト実行モードや、変数の中身を詳細に検査できる機能が搭載されました。
具体的には「このノードを単独実行して中間結果をプレビュー」「変数の内容をMarkdownでプレビュー」といったことがGUI上で可能です。これによりパイプラインの途中経過を逐一チェックしながら安全に調整・改善できるため、複雑な知識処理フローでも安心して作り込むことができます。
既存のDifyユーザーにとって朗報なのは、旧バージョンのナレッジベースから新パイプラインへのスムーズな移行手段が用意されていることです。ワンクリックで従来のナレッジベースを新しいパイプラインアーキテクチャに変換できる機能が搭載されており、過去のデータ資産や設定を活かしつつ新機能へ移行できます。ベータ版とはいえ後方互換性や移行のしやすさにも配慮されている点は、企業利用において安心材料と言えるでしょう。
効果と今後:透過的な知識活用と将来展望
ナレッジパイプラインの導入によって、これまでブラックボックスになりがちだった社内ナレッジの管理が格段に透明化され、デバッグも容易になりました。以前は「なぜこの質問に答えられないのか…」と原因を突き止めるのが難しかったケースでも、各ステップを追いながら調整できるためチューニング時間が大幅短縮できそうだと感じました。
開発チームも「これはゴールではなく始まり」と述べているように、ナレッジパイプラインは今後さらなる拡張の土台となります。将来的にはマルチモーダル検索への対応(テキスト以外の様々なデータ型の扱い)や、人間が途中で介入できるヒューマン・イン・ザ・ループ、企業レベルでのデータガバナンス機能などへの発展も見据えているようです。知識とAIを繋ぐ基盤がこれだけ柔軟になることで、企業内のあらゆる情報資産をAIが活用できる未来がさらに近づいたと言えるでしょう。
キュー駆動型グラフエンジン:ワークフロー実行基盤の強化
もう一つの大きなアップデートが、「Queue-based Graph Engine(キューを活用したグラフエンジン)」の導入です。平たく言えばDifyのワークフロー実行エンジンの抜本的な改良であり、特に並行処理を含む複雑なワークフローの安定性やデバッグ性が飛躍的に向上しています。
並行処理ワークフローの壁
DifyではGUI上でノードを組み合わせてAIワークフローを構築できますが、従来バージョンでは複雑な分岐を持つワークフローの実行管理にいくつか課題がありました。具体的には「並列に動く複数の処理の状態管理が難しい」「エラー発生時に原因を特定しにくい」「実行順序やロジックが固定的で柔軟性に欠ける」といった問題です。私自身、小規模なフローでは問題なく動いていたものが、ノードを増やして並行処理を取り入れた途端に思わぬエラーに遭遇してデバッグに苦労する…という経験が何度かありました。これは裏を返せば、より高度な業務自動化や大規模エージェントを構築しようとすると既存エンジンでは心許ない場面があったということです。
解決策:全タスク集中管理のキューモデル
2.0.0の新グラフエンジンでは、こうした課題を解決するためにワークフロー実行エンジンの根幹が「キュー駆動モデル」に作り替えられました。従来は各分岐が個別に実行され同期を取る形でしたが、新エンジンでは全てのタスクを一元的な「キュー(待ち行列)」に投入し、専用のスケジューラが依存関係と順序を管理します。これによって並列実行時の競合や順序ズレによるエラーが大幅に減少し、ワークフロー全体の実行フローが直感的に把握できるようになりました。
このようなグラフ構造を持ったワークフローは基本的にキューを活用することで処理も早く、スケーラビリティも高く、エラー処理にも強いので、ようやく対応してくれた、という印象があります!
処理は中央キューからワーカー(作業単位)に振り分けられ、負荷に応じてワーカープールが自動でスケールします。例えば同時実行タスクが増えればワーカー数を増やし、暇になれば減らす、といった動的制御が効くため、システムリソースを無駄なく活用しつつスループットを維持できます。並行実行の結果をマージするアグリゲーターも組み込まれており、複数の枝分かれ処理が終わった後に結果を統合して次に進む、という制御もシンプルになりました。
私が実際に試したところ、特に意識せずとも裏で上記のようなタスク統括管理が行われているおかげで、複数分岐のワークフローでも滑らかに流れる印象を受けました。以前は稀に片方の分岐で処理待ちが発生するともう片方も巻き添えで止まってしまう現象を見かけましたが、新エンジンではそういったストールが起きにくくなっているようです。
開発者視点でのメリット:柔軟な実行制御とストリーム対応
新グラフエンジンは内部構造が変わっただけでなく、開発者がワークフローを扱う上での利便性向上も図られています。まず特筆すべきは途中ノードからの実行再開や部分実行が公式にサポートされたことです。従来はワークフローをテストする際、一度最初から最後まで通しで回す必要がありましたが、v2.0では「特定のノードを起点に実行」「途中で一時停止して後から再開」といった柔軟な操作が可能になります。これにより、長いワークフローでも一部だけを検証したり、エラーが起きた箇所から再トライしたりといった開発・デバッグ効率の大幅アップが期待できます。
デバッグ時にはかなり苦労していたので、このアップデートはかなり嬉しいですね。
またストリーミング出力への対応も見逃せません。LLMの応答などトークン逐次生成される出力や、時間のかかるタスクの中間結果などをリアルタイムで次の処理に渡すためのResponseCoordinatorコンポーネントが新搭載されました。これによって、例えば複数のLLMエージェントが同時に応答生成を行うようなケースでも、それらの部分出力を適切に順序制御しながらユーザーに返すことが可能です。以前は並行実行した場合、最終的な結果が揃うまで全て待つ必要がありましたが、新エンジンでは並行処理中でも逐次結果を集約してスムーズに応答できるようになっています。
さらに外部からワークフロー実行を制御する仕組みも強化されました。新たにコマンド機構が導入され、実行中のワークフローに対して「停止」「再開」「強制終了」といったコマンドを送ることが可能です。例えばある条件に達したら途中でフローを止める、リソース上限に達したら緊急停止する、といった高度な実行制御がプログラム的に行えます。現在のベータ版では一時停止・再開機能は今後の対応予定となっていますが、将来的に人間の判断を挟みながらワークフローを進めるようなことも可能になるでしょう。
最後にGraphEngineLayerと呼ばれる新たな拡張ポイントも触れておきます。これはエンジンの機能自体をプラグイン的に拡張できる仕組みで、ワークフローの状態監視やカスタムのモニタリング処理を追加することができます。開発者はコアコードに手を入れることなく、独自のログ収集や外部システム連携を組み込めるため、企業独自の運用監視要件にも柔軟に対応できそうです。
実際に使ってみた感想:安定性と透明性への大きな前進
私は早速この新エンジン上でいくつか社内向けワークフローを再現してみましたが、一言で言えば「堅牢さ」と「見通しの良さ」が段違いだと感じました。複数のAPI呼び出しを並行して行うようなフローでも、各処理のログや進行状況が把握しやすく、万一エラーが発生しても以前より原因箇所を特定しやすくなっています。
特に大きいのは「途中から再実行」が効くことで、長いフローの最後でコケてもデータを活かしつつやり直せるようになった点です。新機能のおかげで開発サイクルが格段に効率化しそうです。
なお、開発チームによれば今回の刷新は性能面での劇的向上を狙ったものではなく、あくまで信頼性・明瞭性・正確性の向上が主目的とのこと。しかし結果として無駄な待ちやエラーリトライが減るため、実質的な処理効率や開発生産性の向上につながっているのは間違いありません。
将来的な計画として、ワークフローの可視化デバッグツール(リアルタイムで実行状態や変数を見られるGUI)や高度なスケジューリング最適化、前述した一時停止・再開やブレークポイントデバッグへの対応、人間の判断を挟むフロー(ヒューマン・イン・ザ・ループ)、サブフローの再利用、さらにはテキスト以外のマルチモーダルデータ対応などがロードマップ上に挙がっているようです。今後のアップデートでこれらが実現すれば、Difyはますます高度で洗練されたAIワークフロー基盤へと進化していくでしょう。
まとめ:ベータ版が示すDifyの方向性と可能性
以上、Dify v2.0.0-betaのアップデート内容を中心に、新機能「ナレッジパイプライン」と「キュー駆動型グラフエンジン」の概要と狙いを解説しました。ベータ版とはいえ、新機能から内部アーキテクチャ改善まで非常に多岐にわたる改良が盛り込まれていたことがお分かりいただけたと思います。私自身、記事執筆にあたり実際に2.0.0-betaを触れてみましたが、Difyの使い勝手と信頼性が確実に向上していることに驚きました。
特に感じたのは、ナレッジ管理とワークフロー実行という基盤部分の強化によって、Difyが対応できるユースケースの幅が一段と広がったことです。これまで難しかった高度にカスタマイズされた社内向けAIシステムの構築や、複雑な並行処理を伴う自動化フローの運用も、現実的なものになりつつあります。実際、知識パイプラインを用いれば社内の大型ドキュメント集約やレガシーデータのAI活用もスムーズに行えそうですし、新エンジンのおかげで長時間&大規模ワークフローの実行も安心して任せられる基盤が整った印象です。細かなUX改善や移行支援も含め、ユーザー目線で痒い所に手が届くアップデートであり、開発チームの丁寧な仕事ぶりに拍手を送りたい気持ちです。
今回のDify 2.0.0-betaは、既存ユーザーはもちろん、これからAIソリューション導入を検討している企業や開発者にとっても非常に示唆に富むリリースだと言えます。「ベータ版だから様子見…」と敬遠するにはもったいないほど完成度が高く、一足先に次世代の機能を試してフィードバックを届ける好機でしょう。今後正式版が出るまでの間にさらなるブラッシュアップが進むはずですので、興味のある方はぜひこのベータ版に触れてみてはいかがでしょうか。私も引き続きDifyのアップデート動向や活用ノウハウを追いかけて、本ブログでは皆さんに共有していく予定です。AIプラットフォームの進化をキャッチアップしつつ、現場に役立つ情報をお届けしていきますので、ぜひお楽しみに!
「AI活用したいけど、どこに頼めばいいか分からない…」とお悩みの方へ。
サステックスは、AI歴10年以上の元Microsoftエンジニアが率いる開発チームです。
PoC〜開発運用まで、ビジネスと技術の両面で支援します。まずは無料で相談してみませんか?
