
データ分析チーム立ち上げ完全ガイド(前編):目的設定、役割、組織設計に関して



こんにちは!サステックスの代表、須藤です。
データドリブンな意思決定が企業競争力を左右する時代において、データ分析チームの立ち上げは多くの企業にとって喫緊の課題です。しかし、単に分析スキルを持つ人材を集めるだけでは不十分であり、明確な目的設定やビジネス課題の特定、最適な組織設計といった多面的な視点が求められます。
本記事では、データ分析チームの立ち上げを成功させるために必要な全体像を体系的に解説しています。
かなり熱量を持って執筆したため、少し読みにくい長文記事となってしまったため、前編、中編、後編と分けて出す予定にしました。他の記事もぜひ読んでいただけると嬉しいです。また、ぜひ自社での分析チーム立ち上げの参考にしていただければ幸いです。
目次
データ分析チーム立ち上げの基盤:明確な目的設定と現状分析
データ分析チームの立ち上げを成功させるためには、まずデータ分析を行う上での基盤を築き、チームの存在意義を明確にする目的設定と、組織の現状を正確に把握する分析を行う必要があります。
データ分析チームの存在意義:SMART原則での明確な目的設定
スキルや体制について議論する前に、絶対的に最初に行うべきステップは、データ分析チームが「なぜ」必要なのかを定義することです。「データ活用が必要だ」といった曖昧な目標は、失敗への近道です。目的は、具体的(Specific)、測定可能(Measurable)、達成可能(Achievable)、関連性がある(Relevant)、期限付き(Time-bound)のSMART原則に則って、設定する事をおすすめしています。
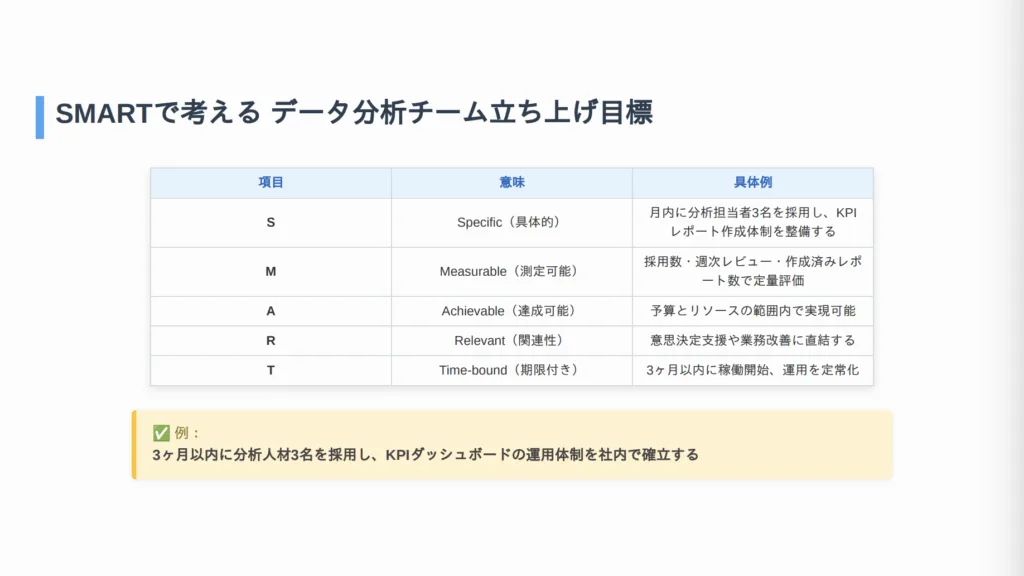
データチームの目的は、組織のビジネス戦略と深く結びついている必要があります。チームの役割は、具体的なビジネス課題の解決や、新たな機会の活用に貢献することです。この目的を定めるプロセスは、単に業務の方向性を決めるだけでなく、組織全体が自社の戦略的な優先事項を見直し、データによる洞察がどう貢献できるかを明確にするきっかけにもなります。
たとえば、最初のステップとして「問いを立てる」ことは重要で、ドメインエキスパートや現場の関係者からの意見が欠かせません。「何を解決したいのか?」という本質的な問いを考えることで、曖昧な「データ分析をしたい」という要望から、具体的なビジネス課題へと焦点を絞ることができます。このプロセスを通じて、組織内にある見落とされがちな前提やズレも浮き彫りになる可能性があります。
ビジネス課題の特定と優先順位付け
データ分析チームは、データ分析が大きな効果を発揮できる課題に焦点を当てるべきです。
具体的には、マーケティング費用の最適化、顧客維持率の向上、業務効率の改善、新たな収益源の特定などが挙げられます。分析的に解決可能であるだけでなく、財務的または戦略的に意味のある影響を持つビジネス課題を特定することが極めて重要です。例えば、10億円のテレビCM予算を10%最適化すれば1億円のインパクトを生み出せるのに対し、年間売上1000万円の商品を10%改善しても、分析組織を維持するには十分な効果とは言えない可能性がある、という例が示されています。
基本的には初期の取り組みとしては、「既存事業の改善」に焦点を当てることが推奨されます。
これらの領域は、多くの場合、既存のデータがあり、成功の指標が明確であるため、チームはより迅速に価値を実証できます。既存の事業領域における明確に定義された問題から着手することは、新設されたデータチームの信頼性を構築し、早期の成功を確保するための戦略的な動きです。このアプローチはリスクを軽減し、チームの長期的な持続可能性と、より探索的または革新的なプロジェクトへの拡大に不可欠な組織的な支持を得るのに役立ちます。特に新設されたデータ分析チームは他の事業チームから「どんな事をしていてどんな利益が出ているのか分かりづらく、批判に合いやすい、」というのもよく聞く話なので、スモールスタートでも早めに成果を出して他チームからも理解してもらう事で長期的にも進めやすい、という点はメリットです。
組織の現状把握:データ成熟度と利用状況の評価
データ分析チームを立ち上げる際には、社内の現在のデータランドスケープを理解する必要があります。
データランドスケープ(Data Landscape)とは、組織内のすべてのデータ資産の「構造」「流れ」「つながり」を俯瞰的に整理・可視化したデータの全体地図のようなものです。
より具体的に記載すると、以下のようなものになります。
| 領域 | 内容 |
|---|---|
| データソース | CRM、ERP、IoT、Webログなど、どんなデータがどこにあるか |
| 保存場所 | データベース、データウェアハウス(DWH)、データレイクなど |
| ETL/ELTプロセス | データがどのように変換・統合されているか |
| ユースケース | BI、AI分析、業務レポートなど、誰が何の目的で使うか |
| セキュリティ・ガバナンス | アクセス権、品質管理、監査ログの有無など |
このランドスケープを整備することで、データのサイロ化(分断)を防ぎ、組織全体での一貫したデータ活用が実現しやすくなります。
また、データランドスケープを理解するだけでなく、データ成熟度評価(現在のデータ活用のレベル(成熟度)の客観的な評価)を行うことも極めて重要です。これは、データ分析チームの設計や戦略に直結する「前提条件」となります。
データ成熟度評価
| 評価軸 | 内容 |
|---|---|
| データソースの整備状況 | どんな種類のデータが、どこに、どの形式で存在しているか |
| データ品質 | データの正確性、完全性、一貫性は保たれているか |
| アクセス性 | 必要な人が適切にアクセスできる仕組みがあるか |
| 既存のツールとインフラ | DWH、BIツール、ETLツールなどの導入状況 |
| データリテラシー | 社員がどれだけデータを理解し、使いこなせているか |
組織のデータ成熟度は、分析チームの戦略や初期スコープに直結します。
- 成熟度が低い企業では、まず「データの整備」「基礎的なレポートの構築」などに多くの時間を使う必要があります。
- 成熟度が高い企業では、すでに整備された環境の中で「予測分析」や「AI活用」などの高度な取り組みに集中できます。
このように、自社の現状を正しく評価せずに高度な分析を求めると、現場は非現実的な期待に押しつぶされ、プロジェクトが頓挫する原因になります。
成功するデータ分析チームの役割
実現場では複数の責務を兼任したり、役職名が違う事も多々ありますが、以下に、データ分析チームにおける主要な役割と責任範囲を紹介します。
主な役割と責任・スキル
表1: データ分析チームにおける主要な役割:責任範囲と必要スキル
| 役割 | 主な責任範囲 | 必要スキル(抜粋) |
|---|---|---|
| データアナリスト | レポート・可視化・ダッシュボード作成、予測分析、有用情報の抽出 | SQL、Excel、統計知識、可視化ツール(Tableau等)、R/Python |
| データサイエンティスト | 機械学習・統計モデリングによる分析、予測モデル構築と解釈 | 数学、統計、AI/MLスキル、プログラミング(Python等) |
| データエンジニア | データ基盤構築、ETL設計、データ収集・変換・統合、クレンジング | ETL/ELT、データベース、クラウド、システム開発スキル |
| プロジェクトマネージャー | 分析プロジェクトの全体管理(進行管理・リソース調整・トラブル対応) | 調整力、計画・管理スキル、コミュニケーション |
| ドメインエキスパート | ビジネス課題の定義、分析内容の方向付け、分析結果の解釈支援 | 専門分野の深い知識、ビジネスプロセス理解 |
| ビジネストランスレーター | 技術とビジネスの橋渡し、アウトプットのビジネス転換、ステークホルダーとの調整 | ビジネス理解、コミュニケーション、技術的背景の理解 |
役割連携とチームとしての機能
実際には条件が整った大企業でない限り、複数の役割の人材を集めてから立ち上げを実施する事は大変なため、
1人で複数の責務(データエンジニア兼データサイエンティスト、など)を兼ねて実施する事が一般的かと思います。そのため、実務では必要な作業が全てカバーされている方が大切です。
また、各役割は独立して動くのではなく、連携が必須です。
例えば、データエンジニアはアナリストやサイエンティストが使用するクリーンなデータを提供し、ドメインエキスパートはアナリストにコンテキストを提供し、プロジェクトマネージャーは全体の取り組みを調整し、ビジネストランスレーターはアウトプットが理解され活用されることを保証します。
特に、「ビジネストランスレーター」という役割は兼任されやすいですが、とても重要な役割とされています。
技術的に優れたデータ分析チームがビジネス価値を提供出来ない主要な理由の一つが、ビジネストランスレーターが欠けている、もしくはビジネストランスレーターの質が低い、といった事が挙げられます。
例えば、「作成したダッシュボードがあまり活用されていない」という一般的な問題に対する解決策として、ビジネスに価値が届くまで説明、ヒアリング、改善を行う「泥臭いポジション」を担うビジネストランスレーターの必要性が重要となります。
よくデータサイエンティストになりたい、という事で技術的なスキルを求める方からのご質問を頂く機会が多いのですが、どちらかというと最低限の技術と進め方を身につけておき、必要になった高度なスキルは実現場で身につけながらプロジェクトを通してキャッチアップしていく事の方が多いです。
最適なデータ分析チームの組織体系の設計
少し硬い話で理屈っぽい話になってしまいますが、データ分析チームのいくつかのパターンの組織体制についても述べていきます。
万能な解決策はなく、最適な設計は組織の状況、規模、データ成熟度、戦略的目標によって異なります。
中央集権型モデル (Centralized Model)
中央集権型モデルでは、すべての人員や技術といったデータリソースが単一の中央データチームに集約されます。
事業部門は、このチームにリクエストを提出する形をとります。
このモデルの利点としては、データリソースと全社戦略との強力な連携、知識共有や実践の標準化(命名規則、ツールなど)の容易さ、若手メンバーへのより良いメンターシップ機会の提供が挙げられます。
特に、小規模な企業やデータ活用の初期段階にある企業にとっては有用です。一方で、事業部門のリクエストに対する応答時間が遅くなるボトルネックとなる可能性や、中央チームがすべての事業領域に関する深いドメイン専門知識を持たない可能性があるという欠点も存在します。
分散型(部門埋め込み型)モデル (Decentralized/Embedded Model)
分散型モデルでは、データアナリスト(もしくはデータサイエンティスト)が特定の事業機能(マーケティング、財務、製品など)に直接組み込まれます。一方で、データエンジニアの中核グループは、データウェアハウスやプラットフォームを管理するために中央集権化されたままである場合があります。このモデルの最大の利点は、部門固有のニーズとの直接的な連携と、組み込まれたアナリストによるより深い文脈理解により、洞察を得るまでの時間が短縮されることです。アナリストは強力なドメイン専門知識を身につけることができます。しかし、部門間で方法論やツールが不統一になる可能性、アナリスト間の知識共有や協力の困難さ、データサイロのリスク、統一されたデータ戦略の維持における課題といった欠点があります。
ハイブリッド型モデル(ドメインベース等) (Hybrid Model, e.g., Domain-based)
ハイブリッド型モデルは、中央集権型と分散型アプローチの要素を組み合わせたものです。
例えば、SnapTravel社の「ドメインベース」構造では、チームのシニアメンバーが特定の事業ドメインのデータ活動を主導し、そのドメインの優先事項をサポートするためにデータエンジニアとアナリストの両方を調整しています。別のハイブリッドモデルとしては、標準、ツール、高度なプロジェクトのための中央「Center of Excellence(CoE)」を設けつつ、一部のアナリストを事業部門に組み込む形が考えられます。
このモデルは、戦略的整合性と標準化を、事業部門の応答性とドメイン専門知識とでバランスさせることを目指します。ドメイン内でのオーナーシップと協力を促進します。しかし、管理がより複雑になる可能性があり、中央チームとドメイン固有チーム間の役割と責任の明確な定義が必要です。また、非常に大規模な組織でのスケーラビリティは依然として懸念事項となる可能性があります。
表2: データ分析チーム組織モデルの比較分析
| モデル | 説明 | 主要な利点 | 主要な欠点 | 最適な組織状況 |
| 中央集権型 (Centralized) | 全てのデータリソース(人材・技術)が単一の中央チームに集約。事業部門はリクエストを提出。 | 全社戦略との連携、知識共有・標準化の容易さ、メンターシップ機会の提供。 | ボトルネック化、応答時間の遅延、事業部門の深いドメイン専門知識の欠如の可能性。 | 小規模企業、データ活用初期段階の企業、全社的な標準化を重視する企業。 |
| 分散型 (Decentralized) | データアナリスト等が各事業機能に組み込まれる。データエンジニアは中央管理の場合も。 | 洞察獲得までの時間短縮、部門ニーズとの連携、アナリストのドメイン専門知識向上。 | 部門間の方法論・ツールの不統一、知識共有の困難さ、データサイロ化、統一データ戦略維持の課題。 | 大規模企業、事業部門の自律性が高い企業、迅速な部門対応を重視する企業。 |
| ハイブリッド型 (Hybrid) | 中央集権型と分散型の要素を組み合わせる。例:ドメインベース、CoEと部門埋め込み型アナリスト。 | 戦略的整合性と部門応答性のバランス、ドメイン内でのオーナーシップと協力促進。 | 管理の複雑化、中央チームとドメインチーム間の役割・責任の明確化が必要、大規模組織でのスケーラビリティ懸念。 | 多くの企業。特に、ある程度の規模があり、戦略的統制と現場の機動性の両立を目指す企業。 |
初期チームの規模とスケーリング
初期段階では、小規模から始めることが推奨されます。例えば、データアナリスト、ドメインエキスパート、プロジェクトマネージャーといった中核的な役割をカバーする2~3人のチームがしばしば推奨されます。
冒頭でも記載しましたが、小規模で始める理由としては、意思決定の迅速化、「はやめに成果を出す」といったことを簡単に達成しやすい、初期投資とリスクの削減、チームがより機敏に学習し適応できることなどが挙げられます。
そして、ビジネスやデータニーズが変化していくにつれて、柔軟にデータ分析チームの組織体系を変更していく、という試行錯誤も重要となっています。初期で設定したデータ分析チームが最終的な解決策ではなくて、継続的に改善・適応をしていく、というのは過去に取り組まれた海外のデータ分析チームを見ていても一般的に行われています。
結論から言うと、理想的にはスモールスタートのチーム(2-3人)で、リスクヘッジを行いつつ、小さいコストかつ改善余地の幅が大きい施策に取り組んでいき、徐々にデータ成熟度を改善していきながら、チームを大きくしていく、といった進め方が理想的です。
まとめ
本記事では、データ分析チーム立ち上げ時における目標設定や、役割、組織体系に関して執筆していきました。
少し理屈っぽい話が多くなってしまいましたが、自社での分析チーム導入の参考にしていただければ幸いです。
記事が長くなってしまいましたが、中編では具体的な分析プロセスの進め方、後編では実際の国内・国外企業のデータ分析チームの成功事例と失敗からの教訓をまとめていく予定です。
「AI活用したいけど、どこに頼めばいいか分からない…」とお悩みの方へ。
サステックスは、AI歴10年以上の元Microsoftエンジニアが率いる開発チームです。
PoC〜開発運用まで、ビジネスと技術の両面で支援します。まずは無料で相談してみませんか?
