
RAG+解説:RAGの精度を向上させる技術論文の紹介! 論文から紐解く仕組みと応用事例



目次
はじめに
こんにちは、サステックスのAIエンジニアの須藤です。
まだジャーナルなどには通っていないようですが、arxivでRAGの精度改善に繋がる面白い論文を見つけたので、本日は「RAG+」という論文を紹介していきます!
AIエンジニアとして、これまで数多くのRAG(Retrieval-Augmented Generation)システムをクライアントのために構築してきました。新入社員のオンボーディング期間を劇的に短縮する社内ナレッジベースや、複雑な問い合わせに対応するカスタマーサポートボットなど業務上でも様々な用途で使われています。
RAGは、正しい文書、つまり「何(What)」を見つけ出すのは驚くほど得意です。例えば、会社の経費精算規定を瞬時に提示してくれます。ですが、従業員がその規定に従って「どのように(How)」経費精算フォームを正しく記入するか、という実践的な部分でユーザーを助けることには苦戦します。
RAGとは?
本題に入る前に、RAGの基本を簡単におさらいしましょう。
RAG、すなわち「検索拡張生成」とは、大規模言語モデル(LLM)が自身の記憶だけに頼るのではなく、外部のデータベースを参照しながら回答を生成する技術です。人間で言えば、記憶力だけで試験に挑むのではなく、教科書持ち込み可の試験を受けるようなものです。このアプローチにより、LLMの弱点であった「ハルシネーション(もっともらしい嘘をつく現象)」の抑制、最新情報への対応、そして企業独自の非公開データの活用が可能になりました。
しかし、LLMは言語モデル、という特性上、事実を見つけるのは得意でも、その事実を使って推論したり、応用したりする方法を示すのが苦手だという点です。例えば、数学の公式は提示できても、数字に関する間違いは以前から指摘されていましたし、法律の条文を検索して提示することはできても、特定のケースにその条文をどう解釈・適用すべきかまでは踏み込めません。実際にRAGを導入したことがあるエンジニアでも、似たようなケースにあたった事があると思います!
これを解決するためのアプローチとして提案されている論文が「RAG+」です。
「応用を意識した推論(application-aware reasoning)」という概念をRAGのパイプラインに組み込むことで、精度向上を実現しているようです。この記事では、技術的な仕組み、論文の評価結果、考えられそうな具体的な応用事例を考えていきます。
ちなみに余談ではありますが、最近gpt-5が出た事によって、数式的な思考力もだいぶ改善されています。
そのため、この論文で提唱されていた問題は解決出来ている可能性もあるため、私も機会があれば、実データで手を動かして、評価してみたいですね。
論文紹介:「RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning」
この論文でのポイントは、「標準的なRAGは「公式の定義」を探してきてくれるのに対して、RAG+では「公式の定義」と「例題と解説」のページをセットで渡す事で、精度上がります!」という点です。
問題定義の簡単な例
論文に記載されている例をそのまま拝借します。
「6人の男子と4人の女子から、少なくとも1人は女子を含めて3人を選ぶ方法は何通り?」
| 取得するナレッジ | アンサー | |
| 標準的なRAG | [公式の定義] 組み合わせ数列の公式 C(n, k)= n!/(k!(n-k)!) | 10人の中から3人を選ぶ、という公式に当てはめて C(10, 3) = 120人 |
| RAG+ | [公式の定義] 組み合わせ数列の公式 C(n, k)= n!/(k!(n-k)!)[例題と解説] 「7人のエンジニアと5人のデザイナーから、少なくとも1人ずつ含めて4人のチームを作る方法は何通りありますか?」という問いに似た例題・解説の取得。 | 公式と例題を取得して、全ての組み合わせから男子の組み合わせを引く、ということが必要なことがわかる。 全ての組み合わせ C(10,3)=120 全ての男子の組み合わせ C(6,3)=20 120-20=100人 |
| 実際の回答 | 100人でRAG+が正解 |
※ただし、例題は分かりやすさのために使われていますが、実際にはGPT-5では推論力が向上しており、この程度の問題は容易に解けます。
RAGとRAG+の違い、お分かりいただけたでしょうか。RAG+は、単に「ルール」を検索するだけでなく、「そのルールが実際にどう使われるのかという実例」も同時に検索して提示する、という案です。RAG+では、2つのコーパスを渡す事で、性能が上がる、としています。
- 知識コーパス (Knowledge Corpus):事実、定義、法則、条文など、従来のRAGが扱ってきた静的な知識を格納します。先ほどの、「数学の公式」に対応するものです。
- 応用コーパス (Application Corpus):知識コーパスの各知識に対応する、具体的な使用例、計算過程、推論の連鎖などを格納します。これがRAG+の革新性の源です。先ほどの、「例題」に対応するものです。
| 特徴 | 標準RAG | RAG+ (応用拡張型RAG) |
| 基本思想 | LLMを外部の知識で拡張する | LLMを外部の知識とその応用方法で拡張する |
| データ構造 | 単一の知識コーパス(文書、記事など) | デュアルコーパス:知識コーパス(事実) + 応用コーパス(実例) |
| 検索プロセス | 1. ユーザーの質問 → 2. 関連する知識を検索 | 1. ユーザーの質問 → 2. 関連知識を検索 → 3. 紐づく応用例を検索 |
| プロンプト | [指示] + [検索した知識] + [質問] | [指示] + [検索した知識] + [検索した応用例] + [質問] |
| 強み | – ハルシネーションの抑制 – 最新情報への対応 – 事実ベースの質疑応答 5 | – RAGの全利点に加え、- 複雑な推論能力の向上 – 多段階の問題解決 – 専門分野での高い性能 |
| 弱み | 知識の応用、多段階の推論、手続き的なタスクが苦手 | – 実装の複雑性が増大 – 高品質な応用コーパスの構築・維持が必要 |
| 例えるなら | AIに教科書を渡す | AIに教科書と解答・解説付きの問題集を渡す |
ベンチマーク
論文では、数学、法律、医療という3つの複雑なドメインにおいて、RAG+が標準的なRAGの性能を一貫して上回ることが示されています。
数学データセット(MathQA)での評価
数学の参考書に「数学の公式」と「例題」と「演習」が乗っていたりすると思いますが、「数学の公式」だけで「演習」を解くんじゃなくて、「数学の公式」と「例題」を使って解いた方が「演習」の正解率が上がる、という感じだとイメージしやすいですね。
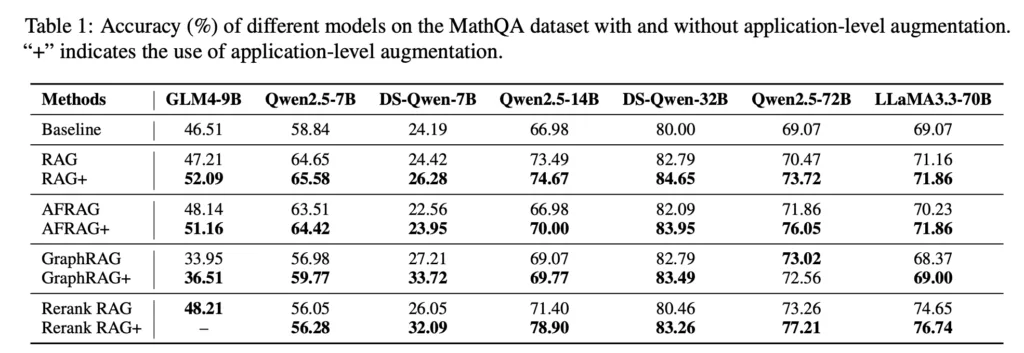
基本的にどの手法でも精度が上がっていそうですね。
ただし、必要なデータが単純に増えていたら、手法というよりデータだけの問題なような気もしますが、そこまで論文は言及していませんでした。
法律データセット(CAIL 2018)での評価
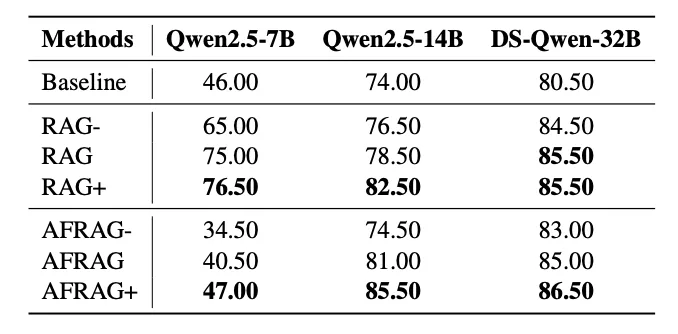
モデルによっては、評価が分かれていますが、一部のアプローチでは性能が上がっている事がわかります。
ちなみに、CAIL 2018は中国の法律のデータセットで、今回の論文では特定の刑法でテストをしているようです。
医療データセット(MedQA)での評価
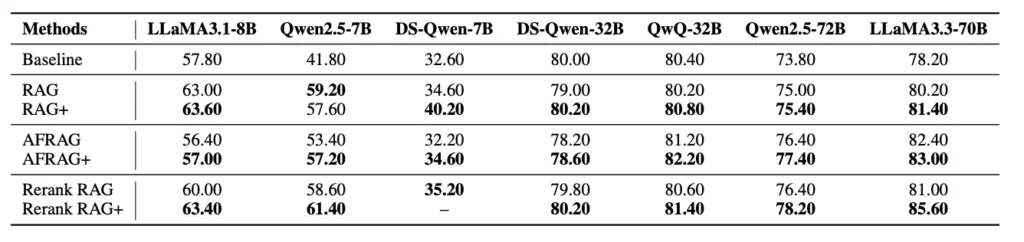
医療系データセットでも全体的に精度向上がされていますが、モデルによっては精度が下がる事もあったようです。
技術解説
知識コーパス (Knowledge Corpus)
まず、知識コーパスですが、これは基本的に標準的なRAGで使われるものと同じです。ここには、宣言的で事実に基づいた情報が格納されます。例えば、法律の条文、医療分野の病気の定義、数学の定理などがこれにあたります。
応用コーパス (Application Corpus)
次に、RAG+で追加された要素の応用コーパスです。これは、知識コーパスにある一つ一つの知識に対して、「それが実際にどのように使われるか」という実例を集めたデータベースです。論文では、この応用コーパスを構築するための主要な2つのアプローチが示されています。
- 応用例の自動生成 (Application Generation)
GPT-4のような高性能なLLMを活用し、各知識に対して応用例を自動で生成するアプローチです。これは、RAG+を大規模にスケールさせる上で非常に重要です。
- 数学の公式に対して:その公式を使った具体的な問題と、その問題を解くためのステップ・バイ・ステップの計算過程を生成します。
- 法律の条文に対して:その条文が適用される架空のケースと、それに対する判決のロジックを生成します。
- 医療の診断基準に対して:その基準に合致する典型的な患者の症例と、診断に至るまでの思考プロセスを生成します。
- 応用例のマッチング (Application Matching)
すでに現実世界に豊富な実例データが存在するドメインで有効なアプローチです。
既存の事例を知識コーパスと紐付けていきます。
- 法律分野:実際の判例(応用例)を、その中で引用されている法律の条文(知識)とマッピングします。
- 医療分野:匿名化された臨床ケースの記録(応用例)を、その診断の根拠となった医療ガイドライン(知識)とマッピングします。
- 金融分野:過去の融資稟議の承認・否認事例(応用例)を、その判断根拠となった社内規定や市場データ(知識)とマッピングします。
この応用コーパスで「実践的な経験のデータベース」を手に入れることで、理論だけではなく、経験に基づいた推論による精度向上を目指す、という材料にしているようです。
推論時の処理に関して
では、このデュアルコーパスは実際の推論時にどのように機能するのでしょうか。
ユーザーが質問をしてから回答が生成されるまでの流れを、ステップごとに見ていきましょう。
1. ユーザーからの質問
ユーザーが複雑な質問を投げかけます。例えば、「17歳の未成年者が親の同意なしに契約を結びました。この契約は日本の法律上、有効ですか?」といった質問です。
2. 知識の検索 (Knowledge Retrieval)
まず、システムは標準的なRAGと同様の動きをします。質問内容に基づいて、知識コーパスから関連性の高い情報を検索します。この例では、日本の民法第5条(未成年者の法律行為)に関する条文がヒットするでしょう。
応用例のマッピングと検索
ここからがRAG+の真骨頂です。システムは、ステップ2で検索された知識(民法第5条)をキーとして、それに対応する応用例を応用コーパスから検索します。ここでは、過去の類似した判例や、「未成年者の契約取り消し」に関する分かりやすい解説事例などが取得されるかもしれません。
構造化プロンプトの生成
役割: あなたは法律の専門家です。
参照法令: [ステップ2で取得した民法第5条の条文]
法令の適用例: [ステップ3で取得した判例や解説事例]
タスク: 以下の事実に基づき、契約が有効か無効(取り消し可能)かを判断し、その理由を説明してください。
事実: [ユーザーの質問内容]回答生成
上記の構造化プロンプトを受け取ったLLMは、手元に「ルール(法令)」と「そのルールの使い方(適用例)」の両方を持っています。これにより、単に「民法第5条により、未成年者の契約は取り消すことができます」と答えるだけでなく、「民法第5条では、未成年者が法定代理人の同意を得ないで行った法律行為は取り消すことができると定められています。ご提示のケースはこれに該当するため、原則として契約を取り消すことが可能です。過去の類似した判例でも、同様のケースで契約の取り消しが認められています」といった、根拠と実例に基づいた、はるかに説得力と深みのある回答を生成できるようになります。
デメリットに関して
メリットは今まで見てきましたが、デメリットも勿論あります。
応用コーパスの構築が大変
ここまで見てきたように、応用コーパスの構築が大変ではあります。論文内では、自動化しているアプローチもありますが、この応用コーパスの質や量によって性能が変化する事は十分に考えられます。個人的にはそもそも自動生成出来るのであれば、単純なコーパスから推論出来そうにも思いました。
また、知識コーパスが増えるにつれて、どうように応用コーパスの運用が増えるため、運用コストも大変になりそうです。
知識コーパス事例と応用コーパス事例のマッチング精度によって精度も変化する
既存のデータと知識を紐づける、というマッチングのアプローチも精度に依存しそうです。ここのマッチングが間違えた場合、ハルシネーションの原因となるため、評価項目が増えて、運用も大変になりそうです。
ただし、すでにマッチングがしてあるナレッジが用意出来るようなユースケースでは活用出来そうに思います。
推論速度が遅くなる
パフォーマンスが良くなったとしても、推論速度が遅くなる可能性が高いです。ここはSLM(小さい言語モデル)で対応することで改善の余地はありそうです。
まとめ
今回は「RAG+」という、RAGの精度向上を目的としたアプローチに関する論文をご紹介しました。
個人的には論文結果にいくつか疑問も感じましたが、実際に試してみる価値はあると考えています。すべての場面で万能に効果を発揮するわけではありませんが、通常の推論だけでは難しいケースや、マッチングに特定の条件が伴う場合には有効に活用できる可能性があるでしょう。
RAGの精度改善には、まず原因を丁寧に分析した上で、適切な改善アプローチを見つけることが欠かせません。
もしRAGの精度改善で課題を感じている方がいらっしゃいましたら、弊社の無料相談をご利用ください。具体的なヒアリングを通じて課題の特定から改善の方向性まで伴走いたしますので、ぜひお気軽にお問い合わせいただければと思います。
「AI活用したいけど、どこに頼めばいいか分からない…」とお悩みの方へ。
サステックスは、AI歴10年以上の元Microsoftエンジニアが率いる開発チームです。
PoC〜開発運用まで、ビジネスと技術の両面で支援します。まずは無料で相談してみませんか?
